
语音识别是一项广泛应用于现代技术中的人工智能领域,它使得计算机或其他智能设备能够通过识别和理解人类语言来进行交互。本文将详细介绍设计JAVA智能语音识别系统的关键要点,以及如何实现高效、准确的语音识别功能。
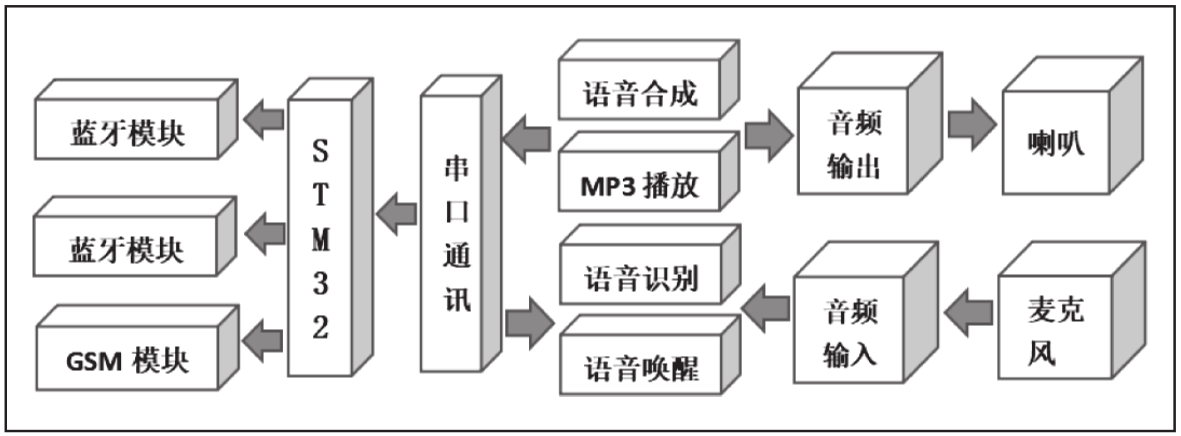
1. 语音信号的采集与预处理
语音信号的采集是整个语音识别系统的第一步。通常使用麦克风等设备采集用户的语音输入,并将其转换成数字信号。预处理是对这些数字信号进行降噪、去除背景干扰等处理,以提高后续处理的准确性。
2. 声学模型的训练与优化
声学模型是语音识别系统中最核心的组成部分,它用来对输入的语音信号进行分析和识别。声学模型通常由HMM(隐马尔可夫模型)和DNN(深度神经网络)等算法组合而成。训练过程包括特征提取、声学模型训练和参数优化等步骤,通过大量的语音数据进行训练,使得系统能够准确识别不同的语音。
3. 语言模型的构建与优化
语言模型用来对识别结果进行语义分析和匹配,以生成最终的文本输出。语言模型通常使用N-gram模型或神经网络模型等方法进行构建,训练过程包括语料库的收集与处理、模型的训练与优化等步骤。优化语言模型可以提高系统的语法和语义识别能力。
4. 上下文理解与对话管理
智能语音识别系统不仅需要识别用户的语音指令,还需要理解其意图并进行合理的响应。上下文理解和对话管理是实现这一功能的关键。通过将用户历史交互数据与识别结果进行匹配和分析,系统能够根据具体场景进行智能的对话管理,提升用户体验。
5. 系统性能优化和部署
为了提供高效、稳定的语音识别服务,系统性能优化和部署非常重要。针对不同的硬件平台和操作系统,可以进行优化调整,以提高系统的响应速度和准确率。同时,对系统进行模块化设计和分布式部署,可以同时处理多个语音请求,提升系统的并发性和整体性能。
总结
JAVA智能语音识别系统的设计要点包括语音信号的采集与预处理、声学模型的训练与优化、语言模型的构建与优化、上下文理解与对话管理,以及系统性能优化和部署。通过科学合理地设计和实现这些要点,可以打造出具有高准确率和稳定性的智能语音识别系统,提升用户交互体验。
